世界模型也被泼冷水了? 邢波等人揭开五大「硬伤」, 提出新范式
- 2025-07-10 02:05:15
- 377
机器之心报道
现在的世界模型,值得批判。
我们知道,大语言模型(LLM)是通过预测对话的下一个单词的形式产生输出的。由此产生的对话、推理甚至创作能力已经接近人类智力水平。
但目前看起来,ChatGPT 等大模型与真正的 AGI 还有肉眼可见的差距。如果我们能够完美地模拟环境中每一个可能的未来,是否就可以创造出强大的 AI 了?回想一下人类:与 ChatGPT 不同,人类的能力组成有具体技能、深度复杂能力的区分。
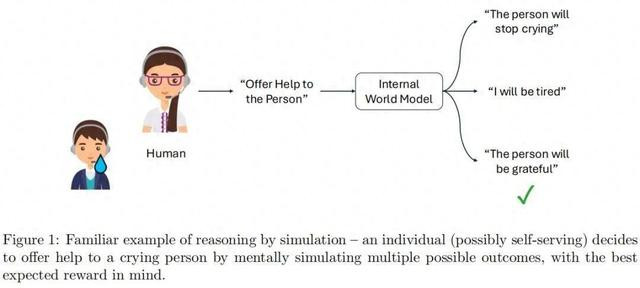
模拟推理的案例:一个人(可能是自私的)通过心理模拟多个可能结果来帮助一个哭泣的人。
人类可以执行广泛的复杂任务,所有这些任务都基于相同的人类大脑认知架构。是否存在一个人工智能系统也能完成所有这些任务呢?
近日,来自卡耐基梅隆大学(CMU)、沙特穆罕默德・本・扎耶德人工智能大学(MBZUAI)、加州大学圣迭戈分校(UCSD)的研究者们探讨了当前 AI 领域最前沿方向 —— 世界模型(World Models)的局限性。
论文:Critiques of World Models
论文链接:https://arxiv.org/abs/2507.05169
研究人员指出了构建、训练世界模型的五个重点方面:1)识别并准备包含目标世界信息的训练数据;2)采用一种通用表征空间来表示潜在世界状态,其含义可能比直接观察到的数据更为丰富;3)设计能够有效对表征进行推理的架构;4)选择能正确指导模型训练的目标函数;5)确定如何在决策系统中运用世界模型。
基于此,作者提出了一种全新的世界模型架构 PAN(Physical, Agentic, and Nested AGI System),基于分层、多级和混合连续 / 离散表示,并采用了生成式和自监督学习框架。
研究者表示,PAN 世界模型的详细信息及结果会很快在另一篇论文中展示。MBZUAI 校长、CMU 教授邢波在论文提交后转推了这篇论文,并表示 PAN 模型即将发布 27B 的第一版,这将是第一个可运行的通用世界模拟器。
对世界模型的批判
一个以 Yann LeCun 为代表的学派在构建世界模型的五个维度 —— 数据、表征、架构、目标和用途。
该学派还为世界模型提出了如图 4 所示的替代框架,其核心思想可以概括为「预测下一个表征」,而非「预测下一个数据」:
作者的观点:
尽管视频等感官数据量大,但其信息冗余度高、语义含量低。相比之下,自然语言是人类经验的高度压缩和抽象形式,它不仅能描述物理现实,还能编码如「正义」、「动机」等无法直接观察的抽象概念,并承载了人类的集体知识。
因此,通往通用人工智能的道路不能偏重于任何单一模态。视频、文本、音频等不同模态反映了经验的不同层面:视频捕捉物理动态,而文本编码抽象概念。一个成功的世界模型必须融合所有这些分层的数据,才能全面理解世界并处理多样化的任务,忽略任何一个层面都会导致关键信息的缺失。
表示:连续?离散?还是两者兼有?
待批判的主张:世界状态应由连续嵌入来表征,而非离散的词元,以便于进行基于梯度的优化。
作者的观点:
仅用连续嵌入来表示世界状态是脆弱的,因为它难以应对感官数据中固有的噪声和高变异性 。人类认知通过将原始感知归类为离散概念来解决此问题,而语言就是这些离散概念的载体,为抽象和推理提供了稳定、可组合的基础 。
理论上,离散符号序列(即「语言」)足以表达连续数据中任意精度的信息,并且如图 5 所示,通过增加序列长度来扩展其表达能力,远比扩大词汇表更高效 。
因此,最佳路径是采用混合表示 。这种方法结合了离散符号的稳健性、可解释性和结构化推理能力,同时利用连续嵌入来捕捉细微的感官细节,从而实现优势互补 。
架构:自回归生成并非敌人
待批判的主张:自回归生成模型(例如 LLM)注定会失败,因为它们最终必然会犯错,并且无法对结果的不确定性进行建模。
作者的观点:
如论文图 6(左半部分)所示,这种被批判的「编码器 - 编码器架构」在潜在空间中进行「确定性的下一嵌入预测」 ,但它在功能上仍是自回归的,需要递归地预测未来状态,因此并未真正避免其声称要解决的误差累积问题 。更关键的是,通过移除解码器来避免重构观察数据,会导致模型学习到的潜在表示与真实世界脱节,难以诊断,甚至可能崩溃到无意义的解 。
更好的方案不是抛弃生成模型,而是采用分层的生成式潜在预测(GLP)架构,这在图 6(右半部分)中得到了展示 。该架构包含一个解码器用于「生成式重构」 ,其核心是一个由「增强的 LLM + 扩散模型」构成的分层世界模型 。这种设计既能通过生成式解码器确保模型与真实数据挂钩,又能通过分层抽象来隔离底层噪声,实现更鲁棒、更强大的推理 。
目标:在数据空间还是潜在空间中学习?
待批判的主张:概率性的数据重构目标(例如编码器 - 解码器方案)是行不通的,因为这类目标难以处理,并且会迫使模型去预测不相关的细节。
作者的观点:
如图 7(左半部分)所示,在潜在空间计算重构损失的方法,理论上存在「平凡解崩溃」的风险 ,即模型可以轻易将所有输入映射为常数来使损失为零,从而什么也学不到 。为了防止崩溃,这类模型不得不依赖复杂且难以调试的正则化项。
相比之下,基于数据空间的生成式重构目标函数,如图 7(右半部分)所示,要求模型预测并重构出真实的下一刻观察数据,并通过「生成式损失」进行监督 。这从根本上避免了崩溃问题 ,为模型提供了稳定、可靠且有意义的监督信号 。
图 8 进一步从理论上解释了,潜在空间损失只是生成式损失的一个宽松的「上界代理」 。这意味着,即使一个模型的潜在损失很低,也不能保证它在真实世界中的预测是准确的,因为它可能遗漏了对任务至关重要的信息 。
用途:模型预测控制(MPC)还是强化学习(RL)?
待批判的主张:世界模型应该用于模型预测控制(MPC),而不是强化学习(RL)框架,因为后者需要过多的试验次数。
作者的观点:
如论文图 9(左半部分)所示,MPC 在决策时需要反复进行「模拟下一个潜在状态」和「基于目标优化动作」的循环 ,这导致其计算开销巨大,难以应对快速变化的环境,并且通常视野有限,难以进行长时程战略规划 。
强化学习(RL)提供了一个更通用、灵活且可扩展的范式,如图 9(右半部分)所示 。它将世界模型作为一个「模拟器」,让一个独立的智能体模型在其中探索并学习 。这个过程是用于「基于目标用 RL 优化智能体模型」 ,将巨大的计算成本从「决策时」转移到了「训练时」 。这使智能体不仅能快速行动,还能通过学习积累长期回报,进行更具战略性的长远规划 。
PAN 世界模型
基于对现有世界模型框架的批评,作者得出了关于通用世界模型设计原则。PAN 架构基于以下设计原则:1)涵盖所有体验模式的数据;2)结合连续与离散表示;3)基于增强的大语言模型(LLM)主干的分层生成建模,以及生成式潜在预测架构;4)以观察数据为基础的生成损失;5)利用世界模型通过强化学习(RL)来模拟体验,以训练智能体。
一个真正多功能且通用的世界模型必须基于能够反映现实世界推理需求全部复杂性的任务。总体而言,PAN 通过其分层、多级和混合表示架构,以及编码器 - 解码器管道,将感知、行动、信念、模拟信念和模拟世界等要素串联起来。作为通用生成模型,PAN 能够模拟现实世界中可操作的可能性,使智能体能够进行有目的的推理。PAN 并不回避原始感知输入的多样性,而是将其模块化和组织化,从而实现对每一层体验的更丰富内部模拟,增强智能体的推理和规划能力。
在训练时,PAN 需要首先通过自我监督(例如使用大语言模型处理文本数据,使用扩散模型处理视频数据)独立预训练每个模块。这些特定于模态和级别的模块在后训练阶段通过多模态数据、级联嵌入和梯度传播进行对齐或整合。
PAN 架构的一大优势在于其数据处理效率,这得益于其采用的多尺度和分层的世界观。事实上,PAN 的预训练 - 对齐 / 集成策略能够充分利用感觉信息简历知识基础,利用 LLM 促进跨模态的泛化能力。
作者概述了一种利用世界模型进行模拟推理的智能体架构。PAN 自然地融入这一范式,不仅作为视频生成器,更作为一个丰富的内部沙盒,用于模拟、实验和预见未来。
最后,作者认为,世界模型不是关于视频或虚拟现实的生成,而是关于模拟现实世界中所有可能性,因此,目前的范式和努力仍然是原始的。作者希望,通过批判性、分析性和建设性的剖析一些关于如何构建世界模型的流行思想,以及 PAN 架构,能够激发理论和实施更强大世界模型的进一步发展。
由 PAN 世界模型驱动的模拟推理智能体。与依赖反应策略的传统强化学习智能体,或在决策时刻昂贵地模拟未来的模型预测控制(MPC)智能体不同,其利用了 PAN 生成的预计算模拟缓存。在决策过程中,智能体根据当前的信念和预期结果选择行动,从而实现更高效、灵活和有目的的规划方式。这种方式更接近人类推理的灵活性。
更详细内容,请查阅论文原文。
- 上一篇:严浩翔给链子南宫问雅摸头
- 下一篇:孩子不爱吃饭带到肯德基医院检查
